LLM Orchestration
Use the right model for each step.
Not every workflow step needs the same model. Blocks lets you route different steps to different LLM providers — based on sensitivity, cost, latency, or task type. Connect OpenAI, Anthropic, or your own private models.
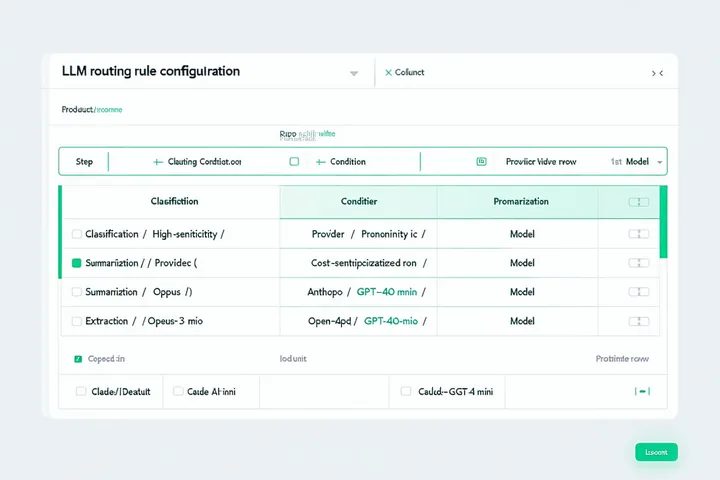
Routing rules that match your requirements
Sensitivity-based routing
Route steps that process confidential data to private or on-premise models. Keep sensitive LLM calls off external APIs.
Cost-optimized routing
Route high-volume, low-complexity steps to cheaper models. Reserve premium models for the tasks that actually need them.
Latency controls
For time-critical steps in a workflow, route to faster models. For async background analysis, use slower but more capable ones.
Structured output enforcement
Define expected output schemas for each LLM step. Blocks validates outputs before passing them to the next workflow step — no hallucinated field names downstream.
Supported providers
Connect the providers you already use, or bring your own via API.
Mix models across one workflow.
Connect OpenAI and Anthropic in the same workflow. Route by step, not by workflow.